Creating a single record from multiple records in SAS
July 09, 2020
1 min
Creating a single record from multiple records in SAS is to transform a data set with one observation per subject and convert it to a data set with many observations per subject.
Why is this required?
It is easier to analyse when all the information per subject is in a single observation, for example, generating a frequency distribution of the data.
In this post, I will demonstrate how to restructure your data sets using the DATA step.
This example uses a small data set -raw_data where each subject ID has one to three diagnosis codes (D1–D3).
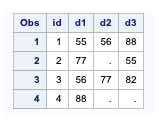
It is difficult to create a frequency distribution of this data.
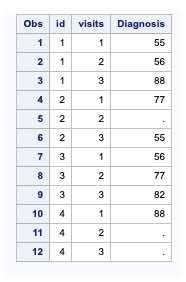
To overcome this, you can create a single Observation from multiple records as below.
data Single_to_Multiple;set raw_data;array d{3};do visits = 1 to 3;Diagnosis = d{visits};output;end;keep id visits Diagnosis;run;
Read the Essential guide for using Arrays in SAS.
The DO loop starts with a Visit set equal to 1. A new variable, Diagnosis, is set equal to the value of the array element D{1}, which is the same as the variable D1, which is equal to 55.
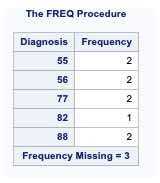
Now, to obtain the frequency of the Diagnosis code, you can use the PROC FREQ procedure as below.
proc freq data=Single_to_Multiple;tables Diagnosis/nocum nopercent;run;