


Table Of Contents


Combining datasets vertically involves stacking one or more datasets. Before combining datasets, It’s important to understand the descriptor portion or structure and contents of your input data sets.
What are Concatenating datasets?
Concatenating data sets is combining two or more data sets by stacking them one after the other to form a single data set.
The number of observations in the new data set is the sum of the number of observations in the original data sets. The order of observation is retained in the new dataset.
What are Interleaving datasets?
Interleaving means combining two or more datasets based on some common variables. Interleaving can be done by a SET statement and a BY statement or by using an index.
The number of observations in the new data set is the sum of the number of observations of the input datasets. The order of the data is based on the common variables specified.
Several approaches can be taken when combining data sets vertically.
- Using a FILENAME Statement
- Using FILEVAR option in INFILE
- Using the DATASETS Procedure’s APPEND Statement
- Using Proc Append
- Using multiple SET statements in the Data step
- Using SQL Union
Method 1. Using a FILENAME Statement
FILENAME statement can be used for interleaving. You can use a FILENAME statement to concatenate raw data files by assigning a single fileref to the raw data files you want to combine. When the fileref is specified in an INFILE statement, each raw data file referenced can be sequentially read into a data set using an INPUT statement.
filename subject ('/folders/myfolders/Data/september.csv''/folders/myfolders/Data/october.csv');data SubjectsCombined;infile subject dsd dlm="," LRECL= 32760;input SubjectName $ Date : ddmmyy8. visits;format date $ddmmyy8.;run;
Method “2”: Using the FILEVAR option in INFILE
The FILEVAR\= option of the INFILE statement can be used for reading multiple files and combining them into a single SAS dataset.
data SubjectsCombined;infile datalines;length readcsv $40;input readcsv $;infile subject dsd dlm="," LRECL=32760 filevar=readcsv end=eof;do while(not eof);input SubjectName $ Date : ddmmyy8. visits;output;format date $ddmmyy8.;end;datalines;/folders/myfolders/Data/september.csv/folders/myfolders/Data/october.csv;run;
In the above example, the first infile statement reads the names of files from datalines and stores on readcsv variable.
As the data step iterates, a new value of ”readcsv” is read from the DATALINES.
In the second infile statement, the options are given concerning the contents of both files. The FILEVAR= option uses readcsv variable, which contains the name of the external file. The external file is opened when the second INFILE statement with the FILEVAR= option is executed.
END= eofin the INFILE statement is set to 1 when the last record is read from the external file.When the value of ”eof” is 1, the DO loop stops looping, and control passes to the next statement following the DO loop.
Method “3”: Using the DATASETS Procedure’s APPEND Statement
The APPEND statement in PROC DATASETS is an efficient method for appending two data tables.
The advantage of using PROC DATASETS’ APPEND statement is that it does not read
any observations from the data set named with the BASE= option.
proc datasets library=work;append base=october data=september;run;
The second dataset data=option is read and appended to the first. Rather than creating a new dataset, the base dataset is replaced with the appended version of the dataset mentioned in the data= option.
Both data sets must have the same variable names with the same length and data type. The APPEND will fail if there are any inconsistencies in the variables.
Method “4”: Using PROC APPEND
PROC APPEND places the observations from one data set to the end of another data set. A New dataset is not created when using PROC APPEND; instead, the datasets mentioned in the BASE= are appended with the data set mentioned in the DATA=.
The difference between PROC APPEND and the APPEND statement in PROC DATASETS is that the default libref is either WORK or USER in the case of PROC APPEND.
In contrast, the default libref for the APPEND statement is the libref of the procedure input library specified in the libname= option of PROC DATASETS.
proc append base=october data=september;run;
Method “5”: Using the multiple SET statements in the Data step
Using the multiple SET statements in a data step is one of the simplest methods for appending two or more datasets. The variable list in the new data set will be a union of the two data sets.
Though this is a simple step, It is important to understand the operations conducted by SAS to carry out the concatenation.
The DATA step will perform read and write operations for each of the observations one at a time from the first data set before reading any observations from the next data set.
This is not very efficient as we are only reading and writing with the observations. However, the advantage is that it can concatenate multiple datasets with less coding.
DATA THREE;SET ONE TWO;RUN;
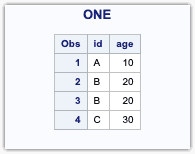 Input Dataset One
Input Dataset One
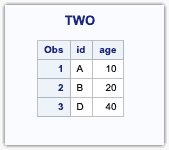 Input Dataset Two
Input Dataset Two
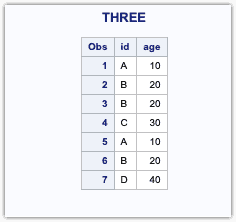 Combined Dataset
Combined Dataset
By, Default the combined datasets will not be sorted. To sort the dataset, we need to provide the BY variable as below.
PROC SORT DATA=ONE;BY ID;RUN;PROC SORT DATA=TWO;BY ID;RUN;DATA THREE;SET ONE TWO;BY ID;RUN;
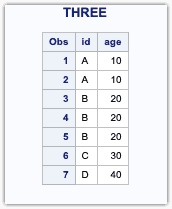 Combined Dataset
Combined Dataset
It is also important to either sort or creates an Index of the input datasets before using the BY statement.
The Variable attributes are determined from the left-most data set(October). Variables unique to the next data set(September) will be added to the PDV on the right and subsequently to the combined datasets (Subject_data). The order of the variables in the data set is not important.
Method “6”: Using SQL Union
Using the SQL UNION is similar to the DATA step, except that all observations from both data sets are read while using multiple SET statements in the dataset. In the case of SQL, they are read into memory first and then written.
Example:
/*Using union*/proc sql;create table three as select * from one union select * from two;quit;/*using union all*/proc sql;create table six as select * from one union all select * from two;quit;
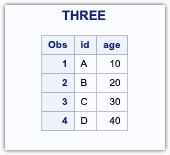 UNION
UNION
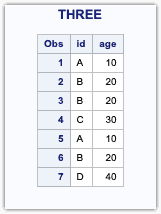 UNION ALL
UNION ALL
UNIONreturns a row if it occurs in the first table, the second, or both and will not return duplicate rows.UNION ALLcan be used to include duplicate rows in the output.
By default, Union will append datasets by column position. Using UNION CORR in PROC SQL, we can instruct SAS to append data sets by name and not by column position. To understand this see the example below.
“Example”:
 Input Dataset Four
Input Dataset Four
 Input dataset Five
Input dataset Five
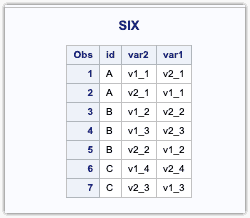 UNION
UNION
Noe that, the observation var2_1 is placed in var2 variable. Similarly, for observations numbers 5 and 7, the observations are interchanged. This is because the UNION appends the datasets by column position.
To overcome this, you can use the **UNION CORR** keyword to append the corresponding columns based on the variable name.
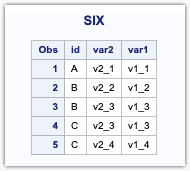 UNION CORR
UNION CORR
That’s it for this article. We would love to hear your valuable feedback and any tips you have. Thanks for reading!!
If you liked this article, subscribe to email alerts for SAS tutorials. You can also find us on Instagram and Facebook.